.jpg)
Вопрос о применении индексов в PostgreSQL — особой структуры данных, которая ускоряет выборку из таблицы, — встал ребром, и я принялся за его изучение. Раньше мне доводилось сталкиваться только с простейшими индексами, так что на полноценное погружение в тему у меня ушло немало часов. Чтобы сэкономить вам время, я собрал ключевую теорию про индексирование в этой статье.
Устройство баз данных и таблиц
Чтобы понять, как работают индексы, посмотрим, как устроены базы данных.Вот так сейчас выглядит наш кластер:
Файлы данных кластера лежат в директории data. Для каждой базы данных есть своя дочерняя папка в data/base, а для каждой таблицы и индекса выделяется отдельный файл. Такой файл таблицы называется Heap File. Он содержит список неупорядоченных записей различной длины и не должен превышать 1GB. Если размер файла превышает 1GB, то создается следующий. Соответственно, наша таблица в базе данных будет храниться уже в двух или более файлах. Сама же таблица состоит из массива страниц. Другими словами, страница — это строки таблицы, а файл — это таблица в базе данных.
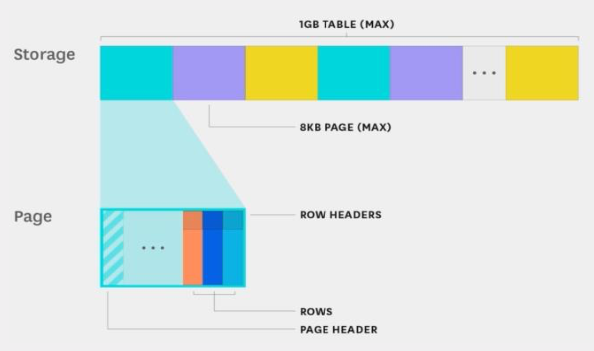
Каждая страница содержит:
✔️ заголовок;
✔️ строки, состоящие из заголовка строки и самой строки;
✔️ ссылки на строки (ctid) — метаданные, состоящие из номера страницы и индекса, с их помощью СУБД может быстрее обращаться к необходимым данным.
Картинка для наглядности:
Вместе с файлом таблицы на сервере лежит файл FSM — Free Space Map. Поскольку максимальный размер страницы — 8КБ, файл FSM помогает серверу сразу понять, куда можно сохранить данные, вместо того, чтобы сканировать все страницы таблиц в поисках свободного места. Важно, что FSM не обновляется при каждом обновлении или удалении строк в таблице. В этом есть своя логика: сохранение старой версии таблицы нужно для корректной работы механизма параллельного доступа, чтобы разные пользователи могли одновременно использовать СУБД.
Механизм TOAST
Сервером запрещается хранение значений строки в разных страницах. В таком случае мы используем механизм TOAST — The Oversized-Attribute Storage Technique. Каждая таблица имеет ассоциированную с ней TOAST-таблицу, в которой хранятся большие значения, нарезанные кусочками по 2 КБ. В столбце нашей исходной таблицы просто помещается ссылка на место в TOAST-таблице, где хранятся реальные значения.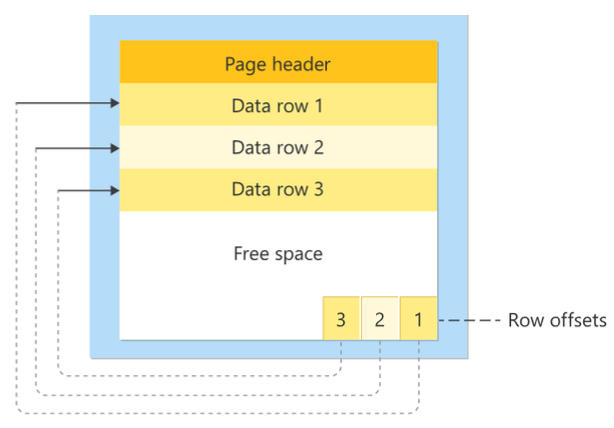
Подробнее о механизме TOAST можно почитать в этом лонгриде от разработчика PostgreSQL.
Fill Factor
Теоретическая база выше должна помочь понять, что такое и как устроен Fill Factor — параметр для индексов в SQL. При создании или перепостроении индекса мы можем задать этот параметр и указать серверу, какой процент каждой страницы мы будем заполнять. По умолчанию это значение равно 100%, то есть Fill Factor пытается забить всё место до предела. Но этот коэффициент не всегда хорош. Если я заполняю все свои страницы до предела, а потом, используя какой-нибудь сложный индекс, пытаюсь вставить строку на эту страницу, то она просто-напросто не поместится. В таком случае серверу придется выполнить довольно много операций для того, чтобы эту строку вместить.В то же время, если использовать классический кластеризованный индекс с увеличивающимся значением ID и вставлять новые строки в конец списка, оставлять большое количество пустого пространства на страницах данных, делая Fill Factor маленьким, тоже неэффективно, поскольку это также будет негативно сказываться на производительности. Наши данные будут более распределены, и нам придется: а) использовать больше страниц в памяти; б) использовать больше места в кэше, что плохо.
Вывод: значение Fill Factor должно быть тем меньше, чем больше и чаще происходят изменения в наших данных.
Что еще важно знать про Fill Factor:
✔️ нельзя применять один и тот же фактор заполнения для всех индексов;
✔️ Fill Factor применяется только к индексам, а не ко всем таблицам;
✔️ не применяется к LOB-страницам, то есть к большим данным, которые хранятся уже не в самих таблицах, а в ассоциированных с ними TOAST-таблицах;
✔️ не влияет на новые страницы, вставленные в конце индекса;
✔️ будучи нетривиальным параметром, используется только опытными базистами.
VACUUM
Для очистки старых ненужных версий строк используется команда VACUUM. Строго говоря, она не возвращает операционной системе память, то есть физически не удаляет такие строки, а лишь отмечает отрезки памяти, которые мы можем перезаписать. А вот полную дефрагментацию таблицы можно осуществить с помощью команды VACUUM FULL. Вместе с файлом таблицы на сервере также лежит файл VM — Visibility Map. Как раз он и показывает наличие/отсутствие «протухших» версий строк. Если в файле хранится значение «1», значит, страница не содержит неактуальные версии строк.
Фрагментация данных нарастает, если не обслуживать базу данных, поэтому необходим периодический запуск VACUUM. Для активно обновляемых баз данных VACUUM рекомендуется проходить каждую ночь. А вот VACUUM FULL лучше использовать только в том случае, когда удалено очень много данных относительно самой таблицы — порядка 30–40%.
Команда VACUUM ANALYZE собирает статистику о содержимом в таблицах и сохраняет результат в специальном системном каталоге. Полученную статистику планировщик запросов может использовать для того, чтобы определить для себя наиболее эффективный план выполнения запросов. VACUUM ANALYZE можно использовать с параметром для определенной таблицы в базе данных.
Autovacuum — бэкграунд-процесс, который осуществляет все операции по очистке и маркировке «протухших» строк автоматически. По умолчанию он всегда включен, и отключать его не рекомендуется.
Индексы: теоретическая база
А теперь переходим непосредственно к индексам.
Индекс — это объект базы данных, который можно создать и удалить, как и любую таблицу. Индексы создаются для столбцов таблиц и даже для представлений. Они позволяют искать необходимые значения без полного перебора. Приведу простую аналогию: когда нам нужно найти в магазине, скажем, книгу Стивена Хокинга, мы идем к стеллажам с надписью «Научпоп». Примерно так же работают индексы.
По сути, индексы можно назвать методом доступа к данным. Они устанавливают соответствие между ключом, то есть значением столбца, который мы индексируем, и строками таблицы, в которых этот ключ встречается. С помощью индексного сканирования мы можем быстро найти те строки, в которых есть данный ключ.
От того, сколько записей фильтрует запрос, зависит, будет ли использован индекс или полное сканирование таблицы. Как правило, если запрос фильтрует небольшое число записей относительно самой таблицы, например, 100 строк в таблице на миллион строк, то мы используем индекс.
Что еще важно знать:
✔️ при любом обновлении проиндексированных данных в таблице индексы также нужно перестраивать;
✔️ индексы требуют затрат на поддержание, так как имеют свою структуру;
✔️ индексы имеют собственные ограничения, в том числе и по поддерживаемым операциям.
Методы сканирования
Существует четыре основных метода сканирования:
1. Последовательное сканирование — sequential scan: просто перебор каждой строки; происходит по умолчанию.
2. Индексное сканирование — index scan: используется при большом наборе проиндексированных данных; потенциально в результирующий набор попадет сравнительно малое количество строк.
3. Исключительно индексное сканирование — index only scan: некоторые индексы вместе с идентификаторами строк хранят сами значения, и этот метод позволяет читать индекс, не обращаясь к таблицам с данными, и забирать результат прямо из индекса. Исключительно индексное сканирование эффективнее простого индексного сканирования. Но здесь есть нюанс: мы обязательно должны посмотреть Visibility Map, чтобы выяснить актуальность записей. Только в том случае, если страница не содержит недействительных строк, мы можем применять исключительно индексное сканирование.
Сканирование по битовой карте — bitmap scan: применяется при относительно большой выборке, когда она слишком большая для того, чтобы мы применяли индексное сканирование, но в то же время не настолько большая, чтобы мы применяли обычное последовательное сканирование каждой строки. При увеличении выборки увеличивается вероятность того, что мы будем читать одни и те же страницы множество раз, и в таких случаях мы используем bitmap scan. Преимущество метода в том, что он работает при поиске более чем по одному индексу.Типы индексов
PostgreSQL поддерживает разные типы индексов для разных задач, в частности:
✔️ B-Tree, он же Balanced Tree, — сбалансированное дерево;
✔️ Hash — хеш-индекс, в отличие от B-Tree, хранит целые числа, они же хеш-коды, а не значения;
✔️ и другие.
Если в pgAdmin написать команду SELECT amname FROM pg_am, то мы сможем посмотреть, какие типы индексов доступны на сервере. Примерно в 95% случаев используется тип индексов B-Tree, так как он применим к любым данным, которые можно отсортировать, и покрывает широчайших класс задач. Остальные типы индексов используются только в исключительных ситуациях, поэтому останавливаться на них подробно не буду.
B-Tree
Когда мы просто создаем индекс командой CREATE INDEX index_name ON table_name (column_name), то по умолчанию создается индекс именно этого типа. B-Tree поддерживает операторы <, >, <=, >=, = и LIKE (‘abc%’). Оператор LIKE (‘%abc’), напротив, не поддерживает. B-Tree индексирует запрос из NULL и NOT NULL.
Сложность поиска по этому индексу логарифмическая. Если наш массив данных отсортирован, мы можем проверить и найти какое-то конкретное нужное нам значение методом деления пополам, то есть прийти к результату через logN элементов проверки. Например, в таблице из восьми строк мы таким алгоритмом найдем нужное значение с помощью трех итераций:

Когда задаем PRIMARY KEY, UNIQUE или просто задаем CREATE INDEX, по умолчанию будет построен B-Tree.
Сравнение типов B-Tree
|
Кластеризованный |
Некластеризованный |
|
|
Порядок хранения |
✔️ Сортирует и хранит данные по правилу сортировки; ✔️ использует первичный ключ для структуризации данных в таблице; ✔️ всегда изменяет физический порядок хранимых данных |
✔️ Не упорядочивает физическое хранение, используя метки для доступа к данным; ✔️ создает свою отдельную структуру данных, которая не зависит от фактической таблицы, для которой он строится |
|
Конечные листья индекса |
Используются для хранения |
Не используются для хранения |
|
Место на диске |
Занимает много места |
Занимает мало места |
|
Скорость доступа |
Быстрый |
Медленный |
|
Дополнительное место на диске |
Не нужно |
Необходимо, так как индекс хранится отдельно от физических данных таблицы |
|
Простота использования |
Не требует явного объявления и создается по умолчанию при определении ключа, то есть в принципе легче в использовании — в том числе в плане синтаксиса |
Требует явного определения; содержит в себе только те столбцы таблицы, по которым определен, поэтому системе запросов нужна дополнительная операция для того, чтобы получить данные из индекса |
|
Сортировка данных |
Возможна |
Невозможна |
|
Создание нескольких индексов на одну таблицу |
Невозможно |
Возможно |
|
Специфика |
Может повысить производительность при извлечении требуемых данных |
Применяется только к неключевым столбцам, которые используются в запросах join |
Как видно из таблицы, у каждого из подвидов B-Tree есть свои преимущества и недостатки. В целом некластеризованные индексы довольно полезны при очень больших наборах данных, потому что они не меняют физический порядок хранимых данных. Подтип некластеризованного индекса — cover index, покрывающий индекс — это индекс, которого достаточно для ответа на запрос вообще без обращения к самой таблице, что, безусловно, быстрее, чем обращение к таблице через обычный индекс. Однако и злоупотреблять этим тоже не стоит: когда мы включаем в покрывающий индекс всё больше и больше информации, он сам становится тяжелее и больше и время поиска по нему увеличивается.
EXPLAIN
Перед тем как построить индекс, нам нужно понять, какой тип индекса использовать. Команда EXPLAIN (SELECT...) позволяет посмотреть план выполнения запроса при использовании того или иного индекса. В свою очередь, команда EXPLAIN ANALYZE (SELECT...) прогоняет запрос и показывает не только план, но и сам запрос, благодаря чему мы можем определить наиболее эффективный индекс для использования.
Подробнее о команде EXPLAIN советую почитать здесь.
Когда индексы не нужны
В отдельных случаях индексы не принято использовать в принципе. К ним относятся:✔️ небольшие таблицы — поскольку методы индексного сканирования и последовательного сканирования практически не будут отличаться друг от друга по времени;
✔️ таблицы с частыми массовыми изменениями UPDATE и INSERT — потому что индексы тоже требуют перестройки, и это будет неэффективно;
✔️ часто обрабатываемые столбцы;
✔️ столбцы с большим количеством значений NULL;
✔️ столбцы с типами данных image, text или varchar(max) — индексация больших тяжелых данных займет слишком много времени.
Заключение
Надеюсь, эта статья сэкономила вам время на первое погружение в тему индексов в PostgreSQL. Главное, помнить, что цель индексирования — ускорить выполнение нашего запроса к базе данных. Если мы пытаемся применить индекс к неподходящему виду данных или используем некорректный тип индекса, то время выполнения запроса рискует, наоборот, увеличиться. Так что к тонкому вопросу индексирования нужно подходить смело, но с умом.
О практической стороне индексирования баз данных в PostgreSQL я расскажу в другой статье. А пока задавайте в комментариях свои вопросы по индексам — постараюсь на всё ответить.
Оригинал статьи читайте на Хабре.